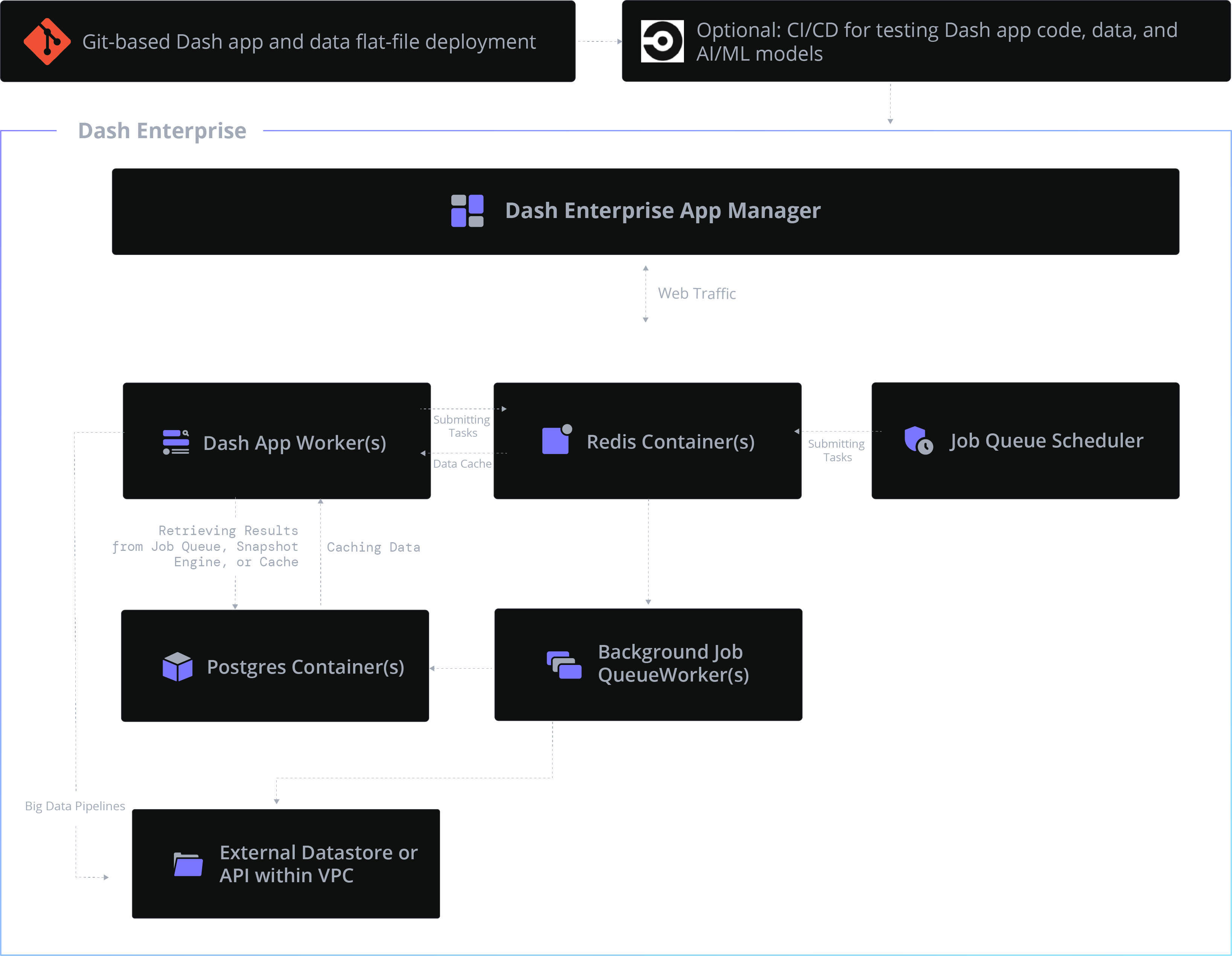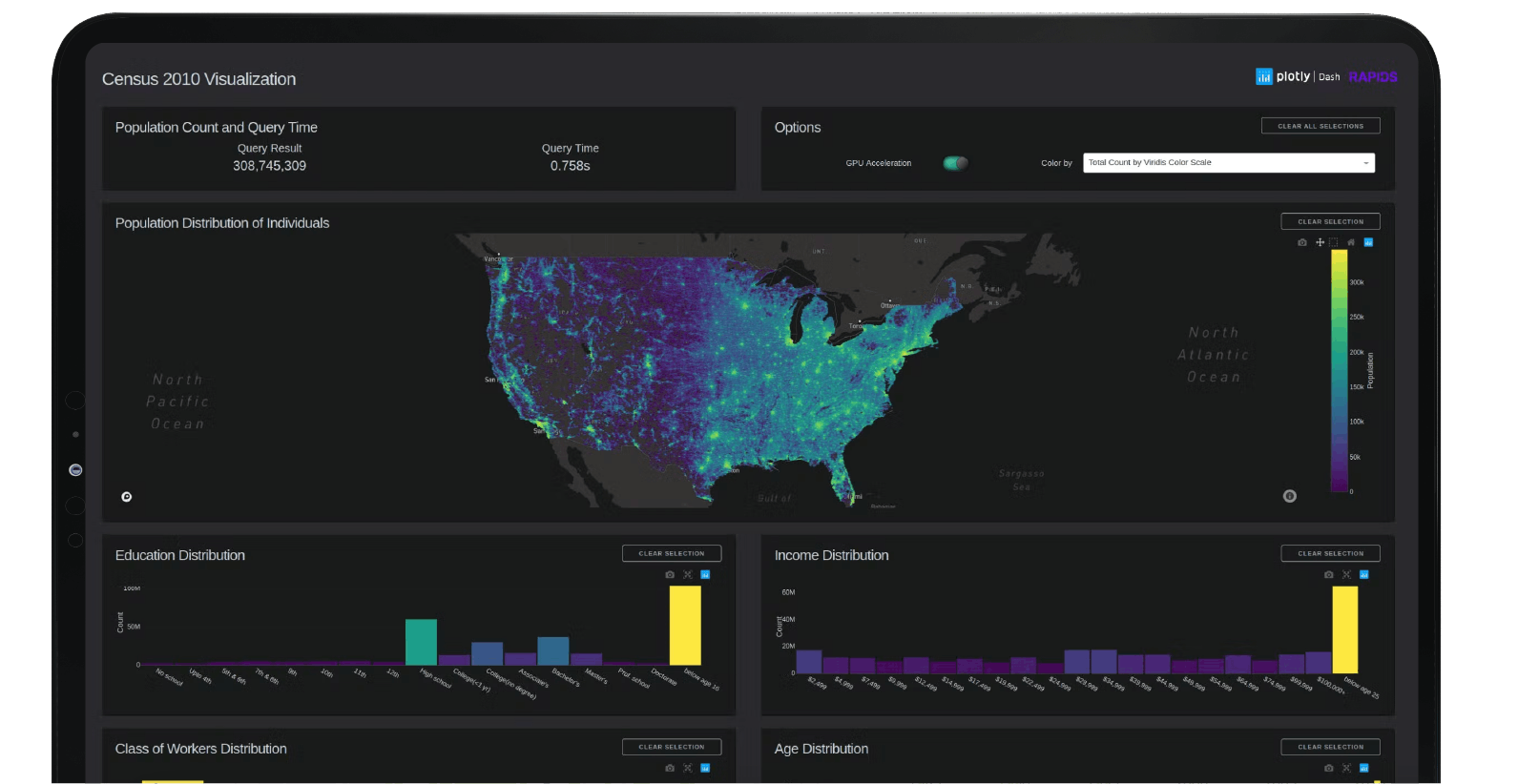
About Big Data Pipelines
Since Python connects to any database, it's easy to empower business users with Dash apps that connect to your databases, query data, perform advanced analytics in Python, and even write back results. As the world's fastest growing language, every database vendor offers a Python connector library (see table below). That's great news for Dash users building analytics apps that connect to databases.
For example, your Dash app might connect to a Snowflake database with Python's Snowflake connector, read customer reviews, perform NLP sentiment analysis, then email a PDF report with Snapshot Engine.
Dash Enterprise ships with battle-tested, plug-and-play Dash app demos for connecting to Snowflake, Databricks, Postgres, Redis, BigQuery, Salesforce, and Redshift. These demos show best practices for connecting and querying databases in Python. Scroll below to demo Python Dash apps that connect to today's most back-end popular databases.

Connector Templates
Dash Enterprise ships with plug & play Dash app templates for connecting to these and other data services in Python. These templates demonstrate best practices such as:
- Using the Dash Enterprise Jobs Queue
- Connection pooling
- Preventing SQL injection attacks
- Reading SQL query results into Pandas dataframes
- Secure database authentication with the Dash Enterprise Secrets Manager

We are not speaking just about reports/dashboards. Dash helps us to organize and combine our data and make it available for a wider spectrum of colleagues, who may require in the future some kind of interaction, such as running finite element simulations for specific parameter combinations.
Senior Simulation Engineer at High-Performance Automobile Manufacturer
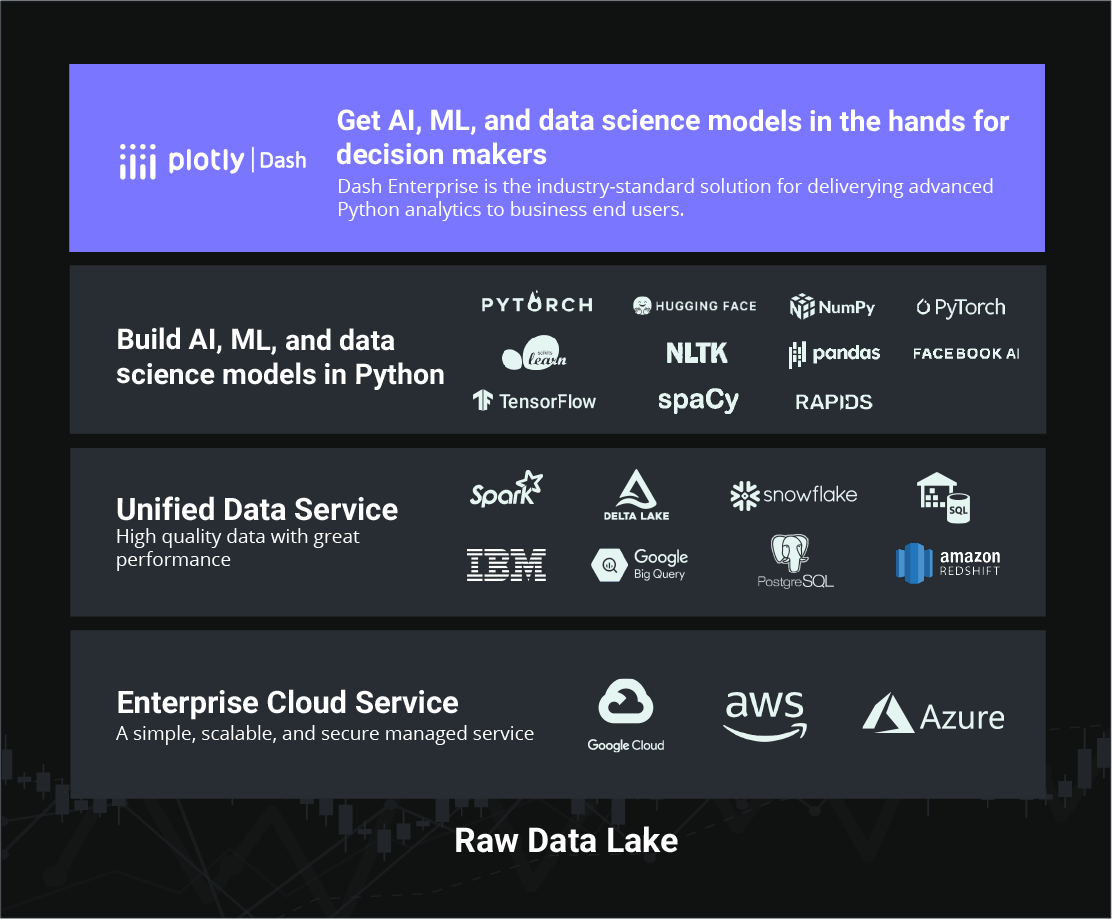
Connect your Dash apps to all major data warehouses.
- Python, R, and Julia supports best-in-class, open-source connection libraries for Snowflake, Amazon Redshift, IBM DB2, Google BigQuery, PostgreSQL, and Azure SQL Data Warehouse, making it simple to connect these data services to your Dash apps. Dash Enterprise comes with connection examples for each of these data warehouses, so you can easily copy/paste the code into your own Dash apps.
- Use Pandas dataframes in Data Science Workspaces or your Dash application code to rapidly filter and visualize data warehouse query results.
- Use the Dash Enterprise Job Queue to sideline long-running data warehouse queries and accelerate your Dash application performance.
Python connects to any database.
This makes it simple to connect your Dash apps to any database, perform AI & ML routines in Python on the data, then deliver these insights to business users as Dash apps.
Database
Python connector library name
Python library downloads per month
Installation command
Dash app example
Documentation
- Databricks
- Databricks SQL Connector for Python
- 1.5M+
- pip install databricks-sql-connector
- Dash-Databricks App
- Python SQL Connector | Integration Github Repository
- MySQL
- mysql-connector-python
- 10M
- pip install mysql-connector-python
- Contact sales
- Querying data
- Postgres
- pyscopg2
- 14M
- pip install psycopg2-binary
- Contact sales
- Basic usage
- Snowflake
- snowflake-connector-python
- 18M
- pip install snowflake-connector-python
- Sentiment analysis app
- Querying data
- Google BigQuery
- google-cloud-bigquery
- 44M
- pip install google-cloud-bigquery
- Contact sales
- Perform a query
- Amazon RedShift
- redshift_connector
- 15M
- pip install redshift_connector
- Contact sales
- Basic example
- MS Azure SQL
- pyodbc
- 19M
- pip install pyodbc
- Contact sales
- Azure SQL Database libraries for Python
- Redis
- redis
- 26M
- pip install redis
- Redis on Dash Enterprise
- redis-py
- MongoDB
- pymongo
- 19M
- pip install pymongodb
- Contact sales
- Tutorial
- Elasticsearch
- elasticsearch
- 16M
- pip install elasticsearch
- Contact sales
- Python Elasticsearch Client
- Postgres, MySQL, SQLite, Oracle, and MS SQL
- sqlalchemy
- 50M
- pip install sqlalechemy
- Contact sales
- SQL Alchemy Dialects
- Salesforce
- simple-salesforce
- 4.9M
- pip install simple-salesforce
- Salesforce Dash app
- Simple Salesforce